KmeansClustering2 Node
KmeansClustering2 node groups the data into clusters based on the values of the two input features.
Category
Terrain Features/Clustering
Inputs
| Name | Type | Description |
|---|---|---|
| feature 1 | VirtualArray | First measurable property or characteristic of the data points being analyzed (e.g elevation, gradient norm, etc... |
| feature 2 | VirtualArray | Second measurable property or characteristic of the data points being analyzed (e.g elevation, gradient norm, etc... |
Outputs
| Name | Type | Description |
|---|---|---|
| output | VirtualArray | Cluster labelling. |
Parameters
| Name | Type | Description |
|---|---|---|
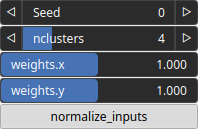
| nclusters | Integer | Number of clusters. |
| normalize_inputs | Bool | Determine whether the feature amplitudes are normalized before the clustering. |
| Seed | Random seed number | Random seed number. The random seed is an offset to the randomized process. A different seed will produce a new result. |
| weights.x | Float | Weight of the first feature. |
| weights.y | Float | Weight of the second feature. |
Example
No example yet
No example available for this node.